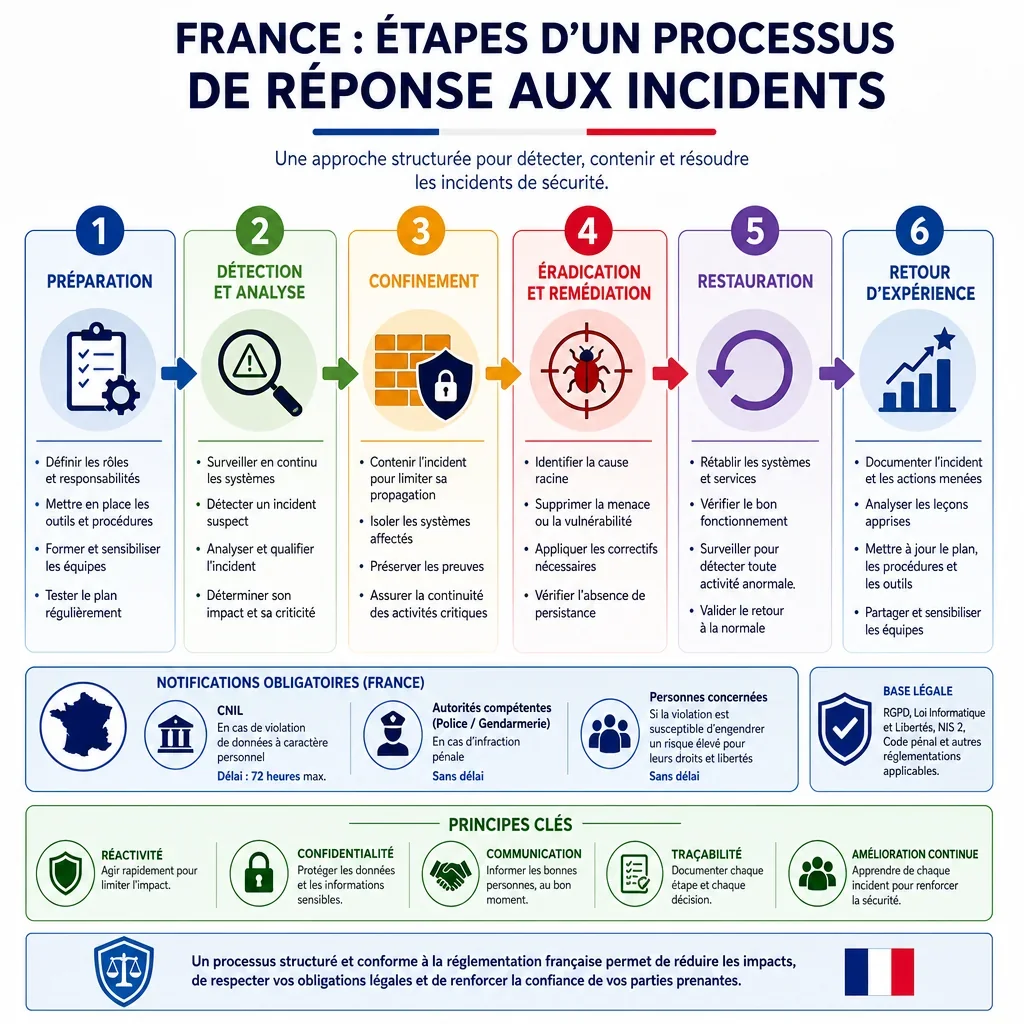
France : Étapes D’un Processus De Réponse Aux Incidents
Étape | Objectif | Actions clés | Éléments à conserver | Priorité |
|---|---|---|---|---|
Préparation | ||||
Désigner l’équipe de réponse à incident | Attribuer les rôles avant la crise. | Nommer RSSI, DPO, juridique, IT, métiers, communication et direction. | Organigramme de crise, fiches de rôle, délégations. | Critique |
Formaliser le plan de réponse aux incidents | Disposer d’une procédure activable immédiatement. | Décrire seuils, rôles, escalade, outils, modèles et contacts. | Plan validé, versions, approbations, historique des mises à jour. | Critique |
Cartographier les actifs critiques | Identifier rapidement les systèmes prioritaires. | Recenser applications, serveurs, données, dépendances, propriétaires et prestataires. | CMDB, cartographie, matrice de criticité, dépendances. | Élevée |
Classer les données sensibles | Évaluer vite l’impact sur les données. | Identifier données personnelles, secrets d’affaires, santé, paie et clients. | Registre de traitements, classification, cartographie des flux. | Élevée |
Maintenir un annuaire de crise | Contacter sans délai les acteurs utiles. | Lister contacts internes, hébergeurs, infogérants, assureur, avocat et autorités. | Annuaire daté, astreintes, contrats, SLA, contacts hors ligne. | Élevée |
Vérifier les sauvegardes restaurables | Garantir une reprise fiable. | Tester restauration, immutabilité, isolement, fréquence et couverture. | Rapports de tests, journaux de sauvegarde, preuves d’immutabilité. | Critique |
Centraliser les journaux de sécurité | Rendre l’investigation possible et rapide. | Collecter logs systèmes, réseau, applicatifs, IAM, EDR et cloud. | Politique de journalisation, rétention, horodatage, accès SIEM. | Critique |
Synchroniser l’horodatage des systèmes | Corréler correctement les événements. | Configurer NTP fiable, fuseaux horaires, horloges serveurs et équipements. | Configuration NTP, traces de synchronisation, écarts constatés. | Élevée |
Organiser des exercices de crise cyber | Tester la coordination avant un incident réel. | Simuler ransomware, fuite de données, indisponibilité ou compromission cloud. | Scénario, chronologie, décisions, écarts, plan d’actions. | Élevée |
Former les équipes aux signaux d’alerte | Réduire le délai de signalement. | Former au phishing, rançongiciel, fuite, compte compromis et anomalies. | Supports, listes de présence, campagnes, taux de signalement. | Moyenne |
Détection | ||||
Surveiller les alertes de sécurité | Détecter rapidement les comportements suspects. | Analyser alertes SIEM, EDR, IDS, antivirus, IAM, cloud et messagerie. | Alertes brutes, tickets, journaux, horodatages, analyste assigné. | Critique |
Recevoir les signalements internes | Transformer les alertes humaines en tickets traitables. | Ouvrir canal dédié, qualifier demandeur, capturer messages et captures d’écran. | Ticket, message source, pièces jointes, en-têtes, captures. | Élevée |
Analyser un courriel suspect | Identifier hameçonnage, malware ou compromission. | Examiner en-têtes, liens, pièces jointes, domaine, réputation et destinataires. | Courriel original, en-têtes complets, IOC, verdict d’analyse. | Élevée |
Détecter une exfiltration de données | Repérer une sortie non autorisée d’informations. | Contrôler flux sortants, volumes, comptes, destinations, API et partages. | Logs proxy, DLP, firewall, cloud, volumes, fichiers concernés. | Critique |
Identifier les signes de rançongiciel | Réagir avant propagation massive. | Chercher chiffrement, extensions anormales, notes de rançon, processus suspects. | Note de rançon, hash, journaux EDR, fichiers témoins, horodatages. | Critique |
Qualification | ||||
Trier l’alerte initiale | Écarter les faux positifs et prioriser. | Vérifier source, périmètre, vraisemblance, criticité et urgence. | Décision de tri, critères, analyste, preuves utilisées. | Critique |
Évaluer la gravité de l’incident | Déterminer le niveau de crise. | Mesurer disponibilité, intégrité, confidentialité, propagation et impact métier. | Matrice de gravité, score, justification, validation direction. | Critique |
Qualifier une violation de données personnelles | Déterminer les obligations RGPD applicables. | Identifier données, personnes, risques, responsable, sous-traitant et délais. | Analyse de risque, registre des violations, décision de notification. | Critique |
Identifier le périmètre compromis | Savoir où agir sans délai. | Lister hôtes, comptes, applications, réseaux, données et tiers affectés. | Liste des actifs touchés, IOC, comptes, adresses IP, preuves. | Critique |
Établir la chronologie initiale | Comprendre l’ordre des événements. | Corréler alertes, logs, connexions, modifications, exécutions et signalements. | Timeline, sources utilisées, hypothèses, zones d’incertitude. | Élevée |
Préserver les preuves numériques | Éviter la perte ou l’altération des preuves. | Copier logs, images disques, mémoire, configurations et artefacts suspects. | Empreintes hash, chaîne de conservation, supports scellés, journal d’accès. | Critique |
Activer la cellule de crise | Coordonner les décisions urgentes. | Réunir décideurs, fixer rythme, ouvrir main courante et arbitrages. | Main courante, participants, décisions, heures, validations. | Critique |
Confinement | ||||
Isoler les machines compromises | Stopper la propagation technique. | Déconnecter réseau, bloquer VLAN, isoler via EDR, sans éteindre inutilement. | Liste des machines isolées, heure, méthode, état initial. | Critique |
Suspendre les comptes compromis | Empêcher l’usage d’identifiants volés. | Désactiver comptes, révoquer sessions, réinitialiser MFA, bloquer jetons API. | Comptes traités, heure, actions IAM, journaux d’authentification. | Critique |
Bloquer les indicateurs de compromission | Limiter communications et réinfections. | Bloquer IP, domaines, hash, URL, règles YARA, signatures et processus. | IOC, règles déployées, périmètre, date, source de renseignement. | Élevée |
Mettre en place une segmentation d’urgence | Protéger les zones non touchées. | Fermer flux, restreindre VPN, filtrer interconnexions, durcir accès admin. | Règles temporaires, schémas réseau, validations, durée prévue. | Élevée |
Contenir l’incident cloud | Limiter l’abus de ressources cloud. | Révoquer clés, isoler instances, bloquer stockage public, vérifier IAM. | Journaux cloud, clés révoquées, snapshots, politiques IAM modifiées. | Critique |
Décider d’une coupure contrôlée | Arbitrer entre continuité et sécurité. | Évaluer impacts métier, sécurité, juridique, clients et réversibilité. | Décision direction, analyse d’impact, heure, systèmes coupés. | Élevée |
Éradication | ||||
Supprimer les codes malveillants | Éliminer la cause technique active. | Nettoyer, réinstaller, supprimer tâches, services, shells et persistance. | Rapports EDR, artefacts supprimés, hash, preuves de nettoyage. | Critique |
Corriger la vulnérabilité exploitée | Empêcher la réexploitation. | Appliquer correctifs, changer configuration, fermer services, durcir accès. | Bulletins, versions, tickets de patch, preuves de correction. | Critique |
Renouveler mots de passe et secrets | Neutraliser les identifiants exposés. | Changer mots de passe, certificats, clés API, jetons, comptes de service. | Liste des secrets renouvelés, dates, propriétaires, validations. | Critique |
Rechercher les mécanismes de persistance | Éviter le retour de l’attaquant. | Contrôler comptes cachés, tâches planifiées, clés registre, webshells, règles mail. | Artefacts trouvés, actions supprimées, scans, captures forensic. | Critique |
Durcir les systèmes touchés | Réduire la surface d’attaque résiduelle. | Désactiver services inutiles, MFA, moindre privilège, filtrage, EDR. | Baseline, écarts corrigés, validations sécurité, résultats de scan. | Élevée |
Valider l’absence d’activité malveillante | Confirmer que la menace est supprimée. | Relancer scans, analyser logs, vérifier IOC, surveiller connexions suspectes. | Rapports de scan, journaux post-nettoyage, validation RSSI. | Critique |
Rétablissement | ||||
Restaurer depuis des sauvegardes saines | Remettre les services en état fiable. | Vérifier sauvegardes, restaurer par priorité, contrôler intégrité et malware. | Sauvegardes utilisées, horodatage, tests d’intégrité, validations métier. | Critique |
Remettre les services en production progressivement | Limiter le risque de rechute. | Redémarrer par lots, contrôler supervision, tests fonctionnels et sécurité. | Ordre de reprise, PV de tests, validations métiers et sécurité. | Élevée |
Surveiller le SI après rétablissement | Détecter une reprise d’activité hostile. | Activer règles dédiées, astreinte, tableaux de bord, seuils renforcés. | Journaux de surveillance, alertes, durée, incidents résiduels. | Élevée |
Obtenir la validation métier de reprise | Confirmer que l’activité peut reprendre. | Tester processus clés, données, interfaces, transactions et utilisateurs pilotes. | PV de recette, réserves, approbations métiers, anomalies restantes. | Élevée |
Clôturer le mode crise opérationnel | Revenir à une gouvernance normale. | Valider stabilité, fermer astreintes exceptionnelles, maintenir surveillance ciblée. | Décision de clôture, critères remplis, risques acceptés. | Moyenne |
Communication | ||||
Informer les collaborateurs | Diffuser consignes et réduire les rumeurs. | Envoyer consignes, canaux autorisés, gestes à éviter, point de contact. | Messages envoyés, destinataires, horaires, validations communication. | Élevée |
Préparer la communication clients | Informer sans aggraver le risque juridique. | Valider faits, impacts, mesures, FAQ, calendrier et porte-parole. | Versions des messages, validations juridique, listes de diffusion. | Élevée |
Notifier la CNIL si nécessaire | Respecter l’obligation de notification sous 72 heures si possible. | Décrire nature, volumes, risques, mesures, DPO et suites prévues. | Déclaration CNIL, accusé, compléments, horodatages, analyse de risque. | Critique |
Informer les personnes concernées si risque élevé | Permettre aux personnes de se protéger. | Expliquer violation, conséquences, mesures, recommandations et contact DPO. | Message, critères, destinataires, preuves d’envoi, exceptions retenues. | Critique |
Alerter le responsable de traitement | Permettre au client de respecter le RGPD. | Notifier sans délai faits, données, mesures, logs et contacts utiles. | Notification client, contrat, SLA, échanges, preuves transmises. | Critique |
Déposer plainte en cas d’acte malveillant | Déclencher les suites judiciaires utiles. | Préparer faits, preuves, impacts, échanges, demandes de rançon et contacts. | Récépissé, dossier de plainte, preuves remises, interlocuteurs. | Élevée |
Déclarer l’incident à l’assureur cyber | Préserver la garantie et obtenir assistance. | Notifier selon contrat, demander accord prestataires, documenter coûts. | Déclaration, numéro sinistre, échanges, factures, conditions de garantie. | Moyenne |
Notifier les autorités sectorielles applicables | Respecter les obligations sectorielles de cybersécurité. | Identifier statut, autorité compétente, délais, format et informations requises. | Analyse d’applicabilité, notification, accusés, échanges avec autorité. | Critique |
Surveiller les communications publiques | Limiter rumeurs, fraude et atteinte réputationnelle. | Suivre presse, réseaux sociaux, dark web, faux messages et usurpations. | Captures, liens, dates, réponses validées, éléments de langage. | Moyenne |
Tenir une main courante d’incident | Tracer décisions, faits et responsabilités. | Noter événements, décisions, acteurs, hypothèses, communications et actions. | Main courante horodatée, pièces jointes, validations, versions. | Critique |
Retour d’expérience | ||||
Organiser le retour d’expérience | Identifier causes, écarts et améliorations. | Réunir acteurs, comparer chronologie, analyser décisions, prioriser actions. | Compte rendu REX, causes racines, écarts, décisions. | Élevée |
Analyser la cause racine | Éviter la répétition du même incident. | Identifier vulnérabilité, erreur, défaut de contrôle ou processus manquant. | Rapport RCA, preuves, hypothèses écartées, actions correctives. | Élevée |
Mettre à jour le plan de réponse | Capitaliser sur l’incident réel. | Modifier seuils, contacts, procédures, modèles, checklists et scénarios. | Nouvelle version, journal des changements, approbation direction. | Élevée |
Suivre le plan d’actions correctives | S’assurer que les failles sont corrigées. | Attribuer responsables, échéances, budgets, preuves et relances. | Plan d’actions, statuts, preuves de clôture, arbitrages. | Élevée |
Archiver le dossier d’incident | Conserver les preuves et justifications. | Centraliser logs, décisions, notifications, preuves, coûts et rapports. | Dossier complet, registre violations, notifications, rapports forensic. | Élevée |
Mesurer les indicateurs de réponse | Améliorer les délais et la qualité. | Calculer MTTD, MTTR, temps de notification, pertes, coûts et indisponibilité. | Tableau de bord, métriques, comparaison avec objectifs, décisions. | Moyenne |
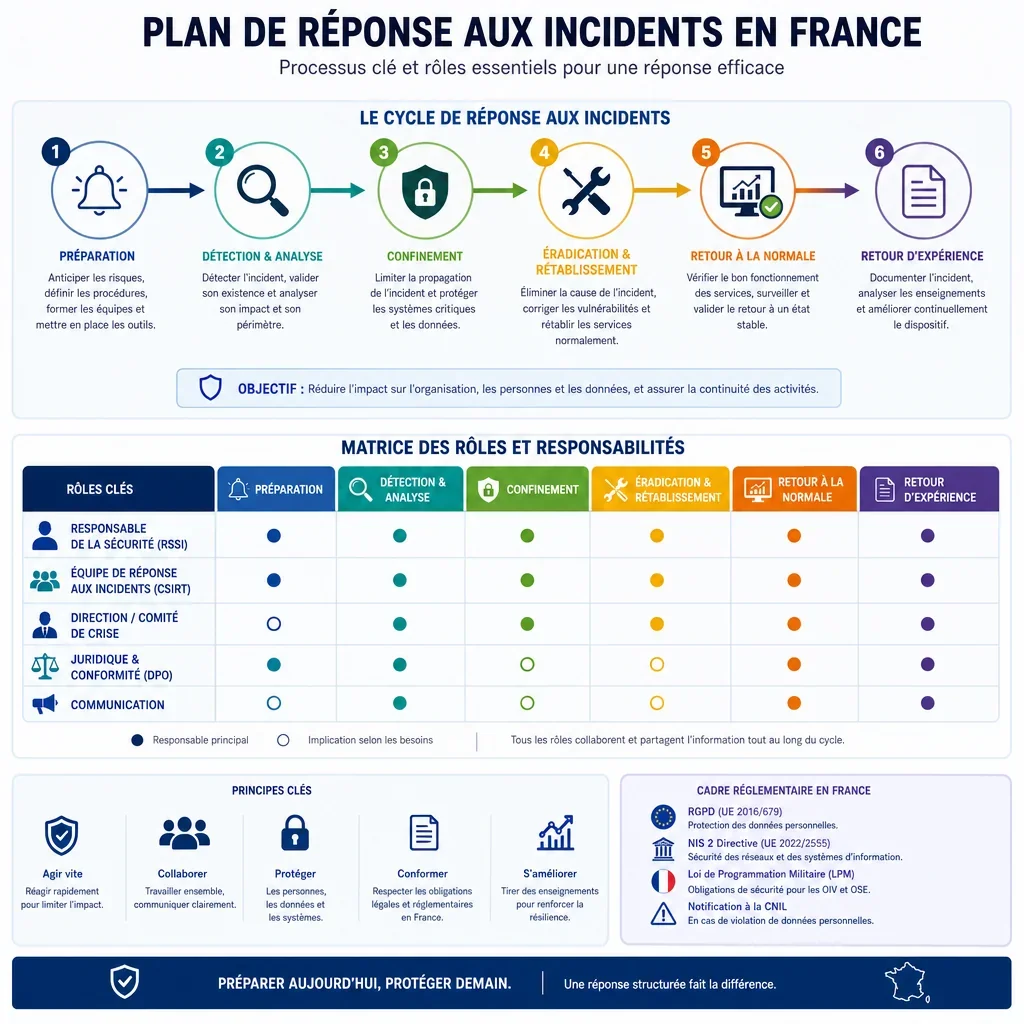
Quelles Étapes Doit Contenir Un Plan De Réponse Aux Incidents En France ?
Un plan efficace doit couvrir tout le cycle de vie : préparation, détection, qualification, confinement, éradication, rétablissement, communication et retour d’expérience. En France, la conservation des journaux, des décisions, des preuves et des validations est essentielle pour démontrer la maîtrise de l’incident, faciliter une enquête interne et documenter les obligations réglementaires.
Quand Faut-Il Notifier Une Violation De Données À La CNIL ?
Si l’incident constitue une violation de données personnelles présentant un risque pour les personnes, le responsable de traitement doit notifier la CNIL dans les meilleurs délais et, si possible, dans les 72 heures, conformément au RGPD. Si le risque est élevé, les personnes concernées doivent aussi être informées. Le registre des violations doit être conservé même lorsqu’une notification n’est pas effectuée.
Pourquoi La Preuve Technique Est-Elle Décisive Après Un Incident ?
Les étapes de collecte, d’horodatage, de chaîne de conservation et de sauvegarde des journaux permettent de préserver la valeur probatoire des éléments techniques. Elles sont particulièrement importantes en cas de dépôt de plainte, de demande d’assurance cyber, d’audit client, de contrôle de la CNIL ou d’intervention d’un prestataire de réponse à incident.
Quels Points Sont Prioritaires Pour Une Organisation Française ?
- Identifier rapidement les systèmes et données touchés pour qualifier la gravité et les obligations légales.
- Isoler sans détruire les preuves afin de contenir l’incident tout en préservant l’analyse forensic.
- Activer une communication maîtrisée avec direction, DPO, RSSI, juridique, métiers, prestataires, clients et autorités.
- Formaliser le retour d’expérience afin de corriger les failles, mettre à jour le plan et prouver l’amélioration continue.
FAQs
Vous Pourriez Aussi Être Intéressé Par